컴퓨터가 사람 언어를 이해하게 하는 기술
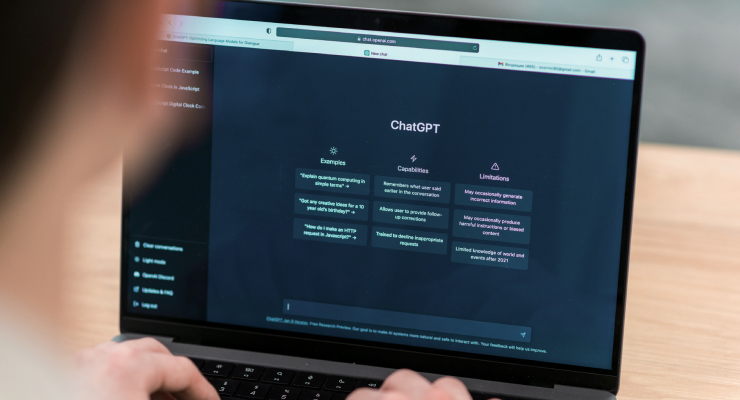
지금 우리의 삶은 인공지능AI과 접목해 있습니다. 특히 생성형 AI인 챗GPT 기술이 대중화되면서 챗GPT를 활용한 기업들이 크게 주목받고 있습니다. 챗GPT는 대표적인 대화형
AI로, 사람의 언어인 자연어 처리NLP, Natural Language Processing 기술을 통해 사람이 질문하면 그 내용을 이해하고 자동으로 답을
제공합니다.
NLP는 인간의 언어를 올바르게 이해하고 해석하는 능력을 가질 수 있도록 컴퓨터에 부여하는 머신러닝(기계학습) 기술을 말합니다. 즉 우리가 일상생활에서 사용하는 언어가 자연어이고,
이러한 자연어의 의미를 분석해서 컴퓨터가 처리할 수 있도록 만들어주는 역할이 바로 NLP입니다. 인류가 어떤 계기로 언어를 쓰기 시작했는지는 명확하지 않지만, 그 언어가 자연적으로
발생했다고 해서 자연어라고 부릅니다. 우리가 알고 있는 거의 모든 언어, 이를테면 한국어·영어·독일어·프랑스어 등이 자연어 범주에 속합니다.
이와 반대로 ‘프로그래밍 언어’는 인공어입니다. 컴퓨터에서 코딩에 사용하는 언어가 바로 그것입니다. 컴퓨터 언어도 자연어와 유사한 부분이 많지만, 여전히 컴퓨터가 이해할 수 없는
방식으로 명령어를 입력해야 하는 한계가 있습니다.
NLP는 자연어 이해, 자연어 분석, 자연어 생성, 오타 검열 등의 기술이 적용됩니다. ‘자연어 이해’는 컴퓨터가 주어진 입력에 따라 인간처럼 언어의 문맥적 의미를 파악하도록
훈련하는 것입니다. 사용자의 감정과 의도를 해석하는 것이죠. 이는 키워드나 기본 패턴을 식별하는 것보다 훨씬 더 복잡합니다.
‘자연어 분석’은 문법에 따라 자연어를 쪼개는 것입니다. 크게 ‘형태소’, ‘구문’, ‘문장’의 과정을 거칩니다. 먼저 우리는 언어를 배울 때 하나의 문장을 명사와 동사, 형용사
같은 품사들로 분해하며 이해하는데, 이 과정이 ‘형태소 분석’입니다. 정확하게 말하면 분해할 때 품사에만 국한하지 않고, 언어에서 의미를 갖는 최소 단위(형태소)까지 분해하는
것입니다. 예를 들어 ‘빵을 먹는 아이’라는 문장이 입력되면 명사(빵), 조사(을), 동사(먹), 어미(는), 명사(아이)로 아주 작은 단위까지 분리합니다.
‘구문 분석’은 조각난 단어들 간의 관계를 찾는 과정입니다. 산산조각 난 단어들 중에서 어디서 어디까지가 주어이고 술어인지, 명사구이고 동사구인지, 단어들 간의 관계를 분석해
문장의 구조를 찾아내는 것입니다. 가령 ‘Time flies like an arrow’라는 문장을 구문 분석할 경우 flies를 명사 또는 동사로 분석하는지, like를 동사 또는
전치사로 분석하는지에 따라 분석 결과가 확연히 달라집니다.
‘문장 분석’은 문장의 뜻을 파악하는 작업입니다. 문법적으로는 맞지만 의미가 잘못된 문장을 파악하는 것입니다. 마지막으로 ‘자연어 생성’은 동영상이나 표의 내용 등을 사람이 이해할
수 있는 자연어로 변환하는 것입니다. 사람이야 아주 오랜 경험을 통해 이러한 규칙을 습득하고 자연스럽게 분석했다지만, 컴퓨터는 언제부터 이런 능력이 가능해졌을까요?











 이번 호 PDF 다운로드
이번 호 PDF 다운로드